Here is some work I'm doing and some work I've done.

Indeed
I currently work at Indeed in Austin as a Taxonomy Analyst. I'm part of a team that works on developing taxonomies and structuring unstructured data for millions of documents.
Indeed helps people find jobs. In our website's own words, "Indeed helps companies of all sizes hire the best talent and offers the best opportunity for job seekers to get hired."

East Austin Digital Archive
Poster
The East Austin Digital Archive (EADA) is a community digital archive hosted at St. Edward's University in Austin, Texas. I helped lay the groundwork by facilitating user interviews, writing technical requirements, making design sketches, and doing bulk photo metadata analysis.
Graphic Design professor Kim Garza has been collecting photos of an East Austin neighborhood since 2011, documenting the texture of the neighborhood and the changes it is undergoing.
This digital archive collects the work of her students (photos and gifs), along with interviews collected by St. Edward's University sociology students. In the future, we plan to expand the archives functionality so that it can accept photos from residents of the neighborhood. Our hope is that the archive will support future research and serve as a model for digital community archives.
My work on the EADA was my capstone project at the UT Austin iSchool. I developed workflows to generate geodata, ingest collections, create and manage derivative images, and format data for ViewShare.

TEL Intranet
I wore several hats at Tokyo Electron (TEL), including content creator, designer, instructor, SharePoint fixer, and user group leader.
I worked on the Collaborative Systems team in the IT department at TEL's US headquarters. Most of my work was in or around the intranet, where I designed, built, and debugged forms, workflows, and user-facing pages. Maintaining the intranet involved fiddling with HTML, XML, CSS, and JavaScript, in addition to SharePoint and Microsoft Office products. We also conducted UI tests with users from within the organization.
I gathered requirements for new solutions as needed, and I explaiedn technical details (and limitations) to our users. I also co-led a weekly user group where we (a) equipped users to build their own solutions and (b) promoted usabilty and design best practices at TEL.
Metadata Usage in the DPLA
Poster | Presentation
We analyzed metadata usage in over 14 million records at the Digital Public Library of America (DPLA) to create metadata usage profiles for the DPLA's content providers.
The DPLA is a non-profit portal and platform for openly available digitized cultural heritage materials. It collects digitized materials from hundreds of individual institutions, each of which sends its materials to one of about 30 DPLA "Hubs". These Hubs add and standardize item and collection metadata before passing the items to the DPLA. However, not all the metadata that ends up in the DPLA is consistent.
We looked at the way "collection" metadata is used by DPLA content providers, and found that there are some odd inconsistencies in what different insitutions and Hubs call a collection. Understanding the way metadata is currently used is the first step toward making the DPLA's collections more usable.
My work on the DPLA was part of Dr. Unmil Karadkar's Metadata Generation and Interfaces for Massive Datasets class at the UT Austin iSchool.
OpenChoice Archive
Report | DSpace archive
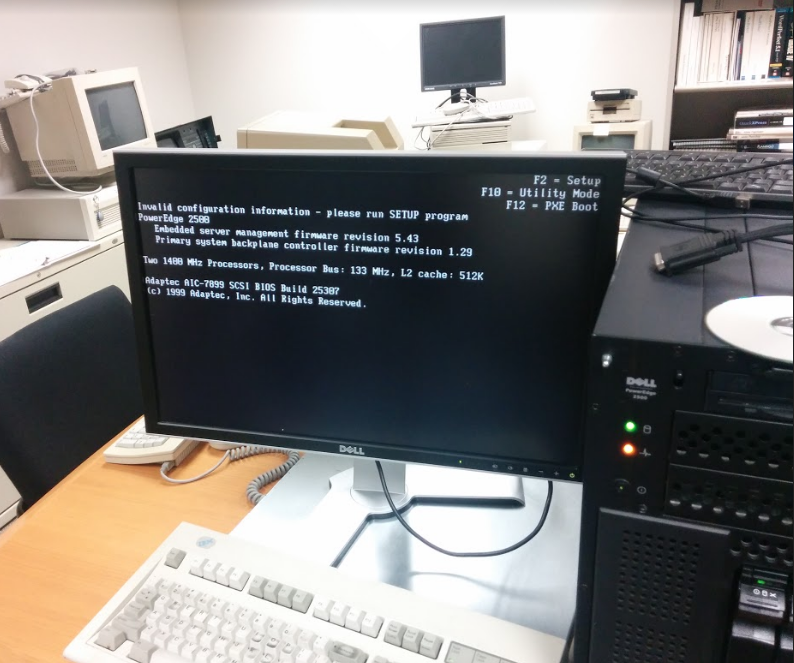
I archived the website for an open web filtering program project at the UT Austin iSchool. My team created a digital archive of the web server used for the project.
The OpenChoice web server was used c. 2006 for a research project at the iSchool. We resurrected the server, created a digital archival copy of it, uploaded the archive to UT's DSpace digital repository, and wrote a final report on our project. I also created an archival copy of the OpenChoice project's original website.
My work on the OpenChoice archive was part of Dr. Pat Galloway's Digital Archiving and Preservation class at the UT Austin iSchool.
Web Scraping and Text Processing
Github | Presentation
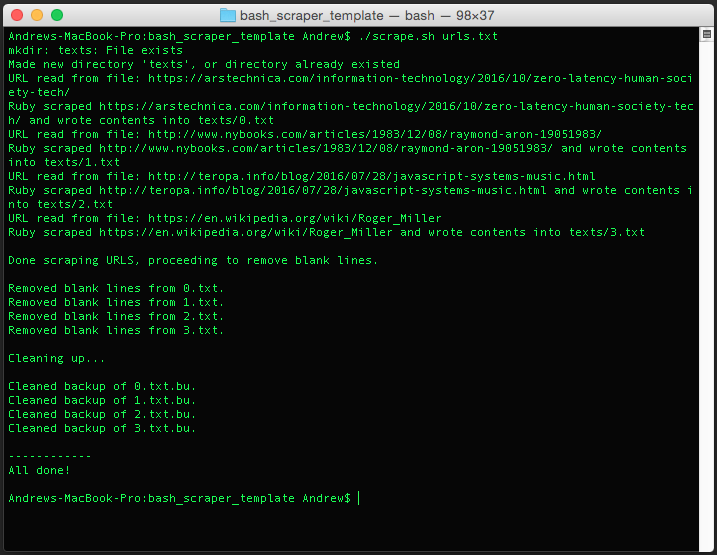
I wrote some scripts to extract and re-format text from webpages.
I used Bash and Ruby to extract all the text from the body of a list of webpages, then used another script to distribute the text into the first column of an HTML table for manual analysis. This project made us 20% more efficient at processing text.